É muito importante, principalmente para um DBA, conhecer e analisar as ferramentas que possam aumentar a performance do banco de dados, isso porque geralmente empresas que possuem DBA trabalham com uma grande quantidade de dados e a velocidade de resposta da aplicação torna-se crítica para seu negócio. Imagine, por exemplo, uma Operadora de Cartão de Crédito, como Visa ou Mastercard: quantos milhões de transações por segundo são realizadas em todo mundo? É fato que um index errado em um banco de dados dessa operadora pode ser fatal para perda de milhões de reais em poucos segundos.
VACUUM
Antes de entender como funciona tal técnica é importante conhecer o funcionamento interno do PostgreSQL para assim ver a real utilidade da mesma.
Você já percebeu que ao deletar registros do seu banco de dados ele não diminui ? Faça o teste: compare o tamanho atual do seu banco de dados com o tamanho após a deleção de muitos registros, você ficará surpreso ao perceber que nada mudou. Então você deve se perguntar: Mas se eu estou deletando, o mais lógico é diminuir o tamanho do banco, certo? Negativo. O PostgreSQL, assim como outros bancos, na verdade não deletam os registros e sim os marca como inúteis, técnica muito comum e utilizada em diversas aplicações, ou seja, se você fizer um “DELETE FROM funcionario WHERE id > 100” e este comando deletar 10 mil linhas, você na verdade estará marcando as 10 mil linhas como inúteis e não deletando fisicamente, o que demandaria muito mais tempo e recurso.
A lógica é a seguinte:é muito melhor ter uma operação rápida do que espaço em disco, sendo assim o banco ficará enorme mais sua performance compensará tal perda de espaço, que hoje em dia acaba não trazendo muito impacto, já que 'armazenamento digital' está barato e acessível.
Todo esse mecanismo é chamado de MVCC (Multiversion Concurrency Control) que garante uma performance melhor ao banco de dados, afinal performance é o ponto chave em aplicações críticas. Quando você realiza um UPDATE, o seu registro é atualizado, correto? Negativo. O que na verdade é feito é uma inserção de outra tupla na sua tabela, com os mesmos dados da tupla original, apenas alterando o que você solicitou no UPDATE, e a tupla anterior (não atualizada) é marcada como inútil, assim como explicamos no DELETE.
Dado todas as explicações acima, chegamos ao ponto chave do artigo: a utilização do VACUUM. Já que temos muitos registros que estão marcados como inúteis, precisamos em algum momento limpar estes, para garantir ainda mais performance em nosso banco e retirar toda sujeira de dados.
No momento em que o comando VACUUM é executado, é feita uma varredura em todo o banco a procura de registros inúteis, onde estes são fisicamente removidos, agora sim diminuindo o tamanho físico do banco. Mas além de apenas remover os registros, o comando VACUUM encarrega-se de organizar os registros que não foram deletados, garantindo que não fiquem espaços/lacunas em branco após a remoção dos registros inúteis.

Figura 1. Executando Vacuum
Na Figura 1 você pode notar um exemplo simples e prático de como funciona o Vacuum:
- Temos na Listagem 1 a lista de todos os registros, incluindo os úteis e inúteis (marcados em vermelho).
- O vacuum deleta todos os registros inúteis (em vermelho), mas após essas deleções serem realizadas, você pode perceber que ficam espaços em branco, exatamente o espaço onde estavam os registros inúteis.
- Por fim, o vacuum encarrega-se de remover esses espaços, garantindo que os mesmos fiquem organizados e em uma disposição correta.
Há ainda um quarto e último passo realizado pelo vacuum, que não está descrito na figura acima. Ocorre que o vacuum também atualiza as estatísticas que são utilizadas pelo otimizador do PostgreSQL para determinar qual a melhor forma de realizar uma busca no banco de dados, porém, a atualização dessas estatísticas vai depender da forma em que o vacuum for executado, o que explicaremos mais a frente do porque.
Listagem 1. Sintaxe do Vacuum
VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] [ tabela ] VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] ANALYZE [ tabela [ (coluna [, ...] ) ]]
Acima você pode ver toda a parametrização do comando vacuum, com suas possíveis opções, então vamos explicar cada uma delas e sua utilidade:
- # FULL : Quando o vacuum é utilizado em conjunto com este parâmetro, então é feita uma limpeza completa de todo o banco, em todas as tabelas e colunas. Este processo geralmente é demorado e evita que qualquer outra operação no banco seja realizada, ou seja, ao realizar um VACUUM FULL você terá que esperar todo processo terminar até realizar um comando DLL ou DML.
- # VERBOSE: Ao ativar esse parâmetro você terá um relatório detalhado de tudo que está sendo feito no comando VACUUM.
- # ANALYSE: Você lembra que citamos anteriormente que o VACUUM em um último passo pode ou não atualizar as estatística que são utilizadas pelo otimizador do PostgreSQL para determinar o melhor método de consulta? Este parâmetro é responsável por habilitar ou desabilitar este tipo de atualização, em outras palavras, ao usar o ANALYSE junto ao seu comando VACUUM ele irá atualizar as estatística do banco de dados a fim de melhorar a performance das pesquisas.
- # tabela: Caso você queira realizar o VACUUM apenas em uma tabela, então você deve especificar explicitamente qual tabela será, caso contrário, apenas deixe este parâmetro em branco e todas as tabelas serão consideradas.
- # coluna: Seguindo o mesmo raciocínio da tabela, caso você deseje realizar o VACUUM em apenas algumas colunas, basta especificar quais são, caso contrário, deixe este parâmetro em branco e todas as colunas serão consideradas.
Algo que você pode ser perguntar é qual a diferença entre o VACUUM sem parâmetros (simples) e o VACUUM FULL (que exige o bloqueio exclusivo das tabelas, ou seja, nenhuma operação pode ser realizada enquanto este comando estiver em processamento). O VACUUM simples apenas remove as tuplas marcadas como inúteis/removidas em processos de UPDATE ou DELETE. Sendo assim, não há necessidade de bloquear as operações no banco. Por outro lado, o VACUUM FULL além de remover essas tuplas inúteis, ainda reorganiza as tabelas, retirando os espaços em branco que ficaram após a remoção dessas colunas, e para tal processo é necessário que o banco não esteja realizando nenhuma operação, por isso o bloqueio do mesmo é necessário.
Caso você utilize o pgAdmin como uma ferramenta para realizar o gerenciamento do seu PostgreSQL, então nele mesmo (sem linha de comando) você poderá realizar o VACUUM, assim como outros processos otimizadores de performance.
O processo é simples: basta você clicar com o botão direito em cima da sua base de dados e depois escolher a opção “Maintenance...”, então você verá uma janela como mostrada na Figura 2.
Figura 2. Vacuum no pgAdmin III
O Vacuum diminui consideravelmente o tamanho físico do banco, mas não só isso, ele também aumenta a performance do otimizador do banco de dados. Além dele, ainda existem outras ferramentas, como falamos em seções anteriores. No gráfico da Figura 3 você pode visualizar de forma mais abrangente a diferença física de espaço em seu banco após realizar processos de otimização do banco, tais como: vacuum, reindex e outros.
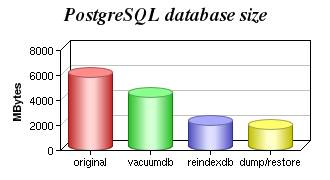
Figura 3. Gráfico PostgreSQL após otimização
O próprio PostgreSQL já possui um processo chamado autovacuum onde você pode deixar que o próprio banco realize o Vacuum Simples (sem o FULL) com frequência, o que é muito bom para base de dados, pois as deleções e atualizações de registros são constantes e você mantêm sua base sempre rápida e sem dados sujos. Por outro lado, a própria documentação original do PostgreSQL aconselha que o VACUUM FULL seja usado como muito cuidado e em casos raros, isso porque o processo demanda muito tempo e pode até causar baixa de performance no banco, em vez de melhor a mesma, isso porque o processo faz algo muito crítico, que é a reorganização de todas as tuplas, retirando os 'gaps' que ficaram após a remoção dos registros inúteis.
Com isso, este artigo teve como principal objetivo demonstrar técnicas mais avançadas do PostgreSQL para análise de performance e otimização do banco, assunto este essencial e obrigatório para DBA's. Vale ressaltar que todas as técnicas descritas neste artigo devem ser usadas com cautela e sempre mediante a uma análise prévia do problema, em outras palavras, não saia executando VACUUM em todas as suas tabelas e bancos antes de analisar a real necessidade de aplicar este procedimento. Como citamos anteriormente, a própria documentação do PostgreSQL aconselha o não uso do VACUUM FULL, que pode ser prejudicial ao banco de dados, se aplicado de forma errônea, obviamente.










